200 Databases, One Pipeline: A Kafka & Debezium War Story
A VP said "Can't you just, like, combine them?" There were 200+ store MySQL databases. I smiled and said sure. Here's what actually happened.
200 Databases, One Pipeline: A Kafka & Debezium War Story

Aerial view of a branching snow-covered landscape — many streams, one destination
A war story from the trenches of retail data infrastructure
The exact words were: "Can't you just, like, combine them?" The speaker was a VP. There were 200+ databases. I smiled and said sure.
What followed was three months of Kafka logs, JVM tuning, and the kind of personal growth that only comes from being humbled by distributed systems at scale.
The Problem: 200+ Databases, One Headache
Our retail operation runs on a distributed MySQL architecture. Every store has its own database instance — think Point-of-Sale transactions, inventory updates, customer records — and for years, this was fine. Each store minded its own business (literally). The data lived locally, reports were batched nightly, and nobody asked uncomfortable questions about real-time.
Then someone discovered dashboards.
Suddenly, leadership wanted to know what was selling right now. Not yesterday. Not in the morning report. Now. They wanted to see transaction volumes, flag missing data, monitor store performance — all live, all central, all from one place.
The naive solution: write a cron job that does a SELECT * FROM transactions WHERE updated_at > last_run on 200+ databases every few minutes and dumps the results centrally. We've all been there. It's charming the first time it falls over at 2 AM because one store's VPN hiccuped and now your loop is hung and the entire pipeline is staring at a timeout.
I needed something better. I needed Change Data Capture.
Enter Debezium: The Database Whisperer
Debezium is one of those tools that sounds deceptively simple in the docs and then immediately humbles you in production. The core idea is elegant: instead of polling your database for changes, Debezium reads MySQL's binary log — the same log MySQL uses internally for replication — and turns every INSERT, UPDATE, and DELETE into a stream of events.
It's like hiring a very attentive court stenographer who sits next to your database 24/7 and writes down everything that happens, in order, with timestamps, and then publishes it to a message broker so the rest of your architecture can react.
That message broker? Apache Kafka.
A Brief, Honest Description of Kafka
Kafka is a distributed event streaming platform that your team will either love or spend three weeks trying to configure before they love it. Think of it as an infinitely patient inbox that can handle millions of messages per second, remembers everything, lets multiple consumers read the same data independently, and never complains — unlike certain colleagues.
Together, Debezium + Kafka form a CDC pipeline: Debezium reads database changes and publishes them to Kafka topics; consumers read from those topics and do something useful with the data.
In our case, something useful meant writing everything into a central MySQL database that our reporting tools (Power BI, internal dashboards, monitoring alerts) could query freely.
The Architecture
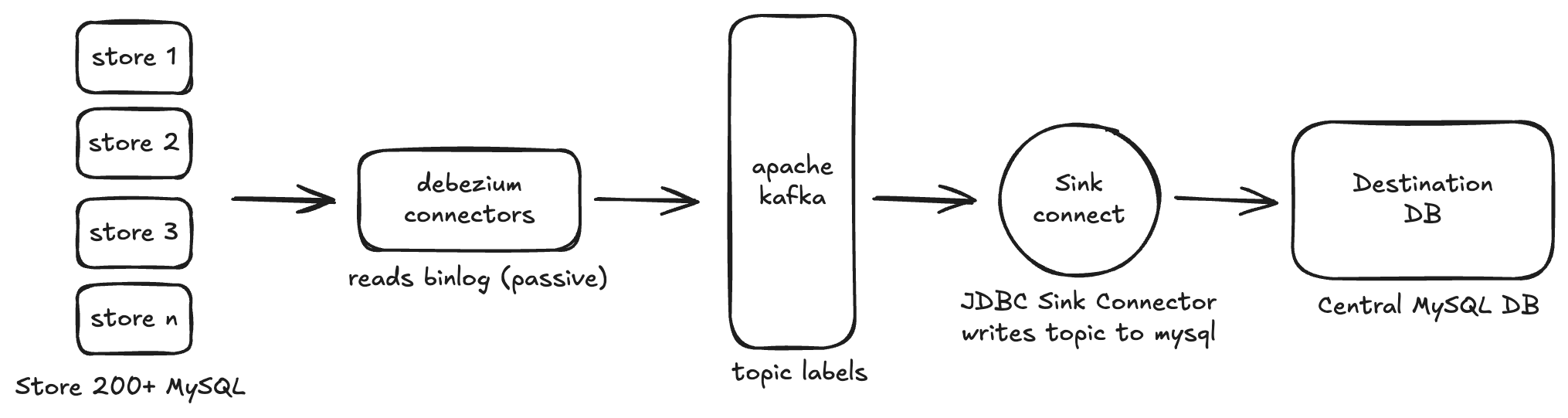
CDC Pipeline — 200 store MySQL databases streaming into a central DB via Debezium and Kafka
Each store's Debezium connector watches the binary log of that store's MySQL instance and publishes change events to dedicated Kafka topics — one topic per table, per store, following a naming convention like store.{store_id}.{table_name}.
A Kafka Connect JDBC Sink connector then reads from those topics and upserts the records into the central database. Every transaction, every inventory update, every record change — streamed, in order, in near real-time.
On paper: beautiful. Clean. Elegant. The kind of architecture diagram you'd print and frame.
In practice: a masterclass in humility.
The Part Nobody Puts in the Architecture Diagram
Memory, Glorious Memory
The first thing Kafka Connect will do when you deploy it is consume all available heap memory and die. Not maliciously — just enthusiastically. The JVM defaults are sized for a developer laptop, not a production system ingesting from 200 concurrent connectors.
Lesson learned: tune your JVM. Before you do anything else. Set KAFKA_HEAP_OPTS, allocate generous but not greedy amounts of heap, and monitor your GC logs like they owe you money. We ended up with:
KAFKA_HEAP_OPTS: "-Xms2G -Xmx4G"...after the third spontaneous container death. We got there eventually.
Binary Log: It Has to Actually Exist
Debezium reads the MySQL binary log. MySQL does not enable binary logging by default. This seems like the kind of thing that would be obvious, but when you're configuring connector number 47 at 11 PM, it's easy to overlook the fact that Store #203 has a freshly provisioned DB with no binlog_format=ROW in its my.cnf.
The connector will fail silently (or loudly, depending on your error tolerance config) and you'll spend 45 minutes staring at logs before someone on the team asks, "wait, is binlog even on?"
It was not.
We eventually scripted a pre-flight check that verified binary logging, log retention settings, and the Debezium user's replication privileges before registering any connector. Automation is the antidote to midnight regret.
Topic Naming Is an Unsolved Problem in Computer Science
When you have 200+ source databases each with a dozen or more tables, your Kafka topic count balloons fast. We had to establish strict naming conventions, enforce topic creation policies, and configure partitioning thoughtfully so consumers could parallelise without stepping on each other.
The format we settled on: {environment}.{store_id}.{schema}.{table}. Verbose? Yes. Unambiguous? Absolutely. The 20 extra characters per topic name saved us countless hours of "wait, which store is this event from?"
The Offset Problem (Or: Why Idempotency Is Your Best Friend)
Kafka tracks consumer offsets — essentially bookmarks for how far each consumer has read in a topic. When a connector restarts (and it will restart — connectors restart like it's a hobby), it picks up from the last committed offset.
What this means in practice: you might process the same event twice. Or three times if you're unlucky. Your central database sink must be idempotent — upsert, not insert. If you're doing raw INSERTs and a connector replays 10,000 events after a restart, congratulations on your duplicate data problem.
The fix: primary key-based upsert logic in the sink. Every event is treated as "the truth about this record at this moment in time", and the central DB reflects accordingly. Duplicates become non-events. Sleep improves.
Connector Configuration: There Are a Lot of Properties
A Debezium MySQL connector has approximately one thousand configuration properties. I'm exaggerating, but not by much. The important ones for production:
initial snapshots the whole table first, then switches to streaming. Choose wisely based on table size.Monitoring: The Dashboard That Watches the Dashboard Builder
Once the pipeline was live, we built a monitoring layer on top. Because 200+ connectors running in production and you not knowing if one of them silently fell over three hours ago is not a situation you want to discover during a board meeting.
Our monitoring checks:
RUNNING, PAUSED, or FAILED. We poll this and alert on failures.The monitoring system caught three real incidents in the first two weeks of operation. That's three issues that would have otherwise been discovered the hard way — by a manager asking "why is Store 47 not showing up in the reports?"
Was It Worth It?
Let's be honest about what we traded.
What we gained:
What we gave up:
Would I do it again? Without hesitation. The alternative — a cobbled-together polling system with cron jobs, retry logic, and prayers — doesn't scale. Kafka + Debezium scales. It handles load, it handles failures gracefully, it handles new stores without architectural surgery. Once it's running and tuned, it just works.
The two crying sessions were honestly worth it.
Final Thoughts for the Road
If you're considering a similar setup, here's the condensed wisdom:
Data infrastructure is not glamorous. Nobody's going to write a Medium post about your perfectly tuned max.queue.size. But when the dashboards load in real-time, when the alerts fire exactly when they should, when a store manager can see their live transaction volume from their phone — that's the payoff.
That's the whole point.
Written from lived experience in retail data infrastructure. The author's opinions are his own. The connector failures were very much real.
Follow me on X — @_72kb
More Stories
2025 in Retrospect
The last day of the year. Reflections on habits, discipline, growth, and the messy journey of becoming better. Here's to doing it, not just saying it.
4 min read →CloudHow We Cut Our AWS Bill by 40%: The Full Breakdown
A retail company running servers 24/7 for a business that closes at midnight. The biggest saving wasn't sophisticated — it was just turning things off. Plus NAT Gateways, right-sizing, and VPN cleanup.
5 min read →